Nitrogenous Bases: Unlock the Secrets of DNA! 🧬
The very blueprint of life hinges on the intricate dance of molecules, and at the heart of this dance lie nitrogenous bases. These organic compounds, including adenine, guanine, cytosine, and thymine (or uracil in RNA), are the fundamental building blocks of DNA and RNA. Rosalind Franklin's pioneering work on X-ray diffraction provided critical insights into the structure of DNA, revealing the crucial role of nitrogenous bases in forming its double helix. The arrangement of these bases dictates the genetic code, which then directs the synthesis of proteins within the cell. Institutions such as the National Institutes of Health (NIH) dedicate significant resources to researching the functions and interactions of nitrogenous bases, ultimately contributing to our understanding of diseases and potential therapeutic interventions.
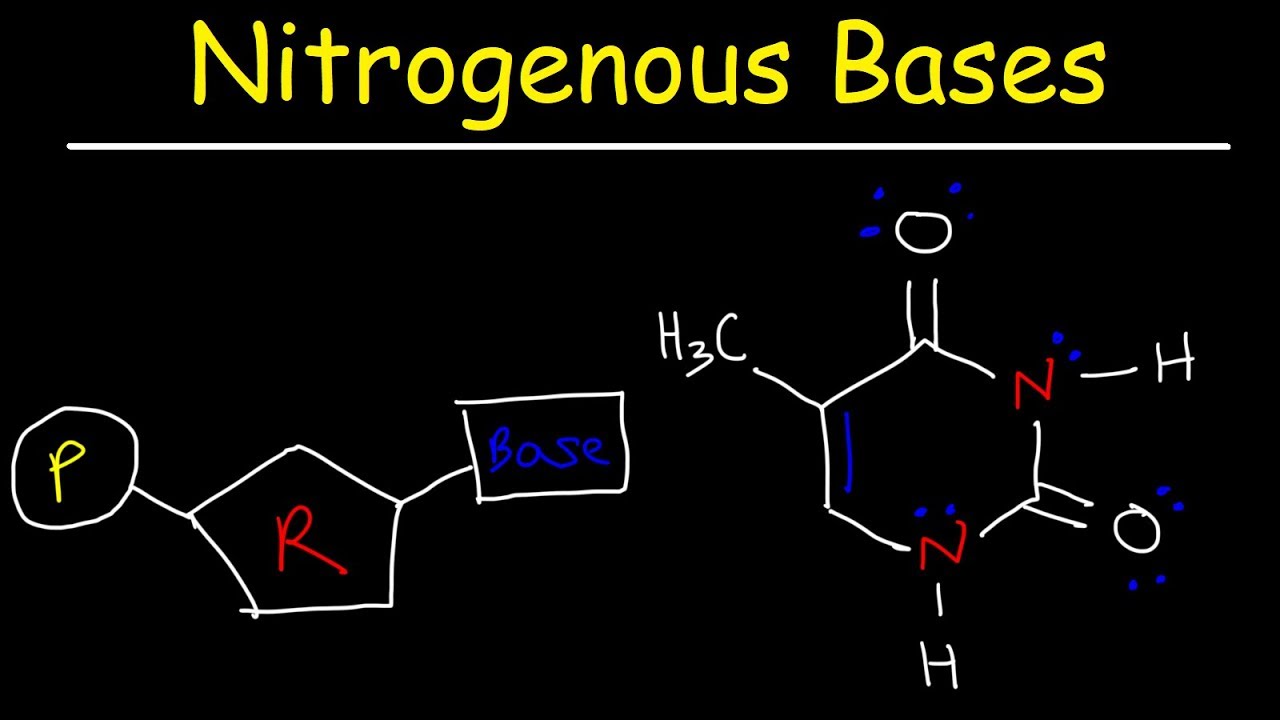
Image taken from the YouTube channel The Organic Chemistry Tutor , from the video titled Nucleosides vs Nucleotides, Purines vs Pyrimidines - Nitrogenous Bases - DNA & RNA .
Life, in all its astonishing complexity and diversity, is underpinned by a remarkably simple code. This code, the blueprint for every living organism, resides within the elegant structure of DNA (Deoxyribonucleic Acid).
Think of DNA as the instruction manual for building and operating a living thing. Understanding its components is key to unlocking the secrets of life itself.
DNA: The Molecule of Life
DNA is the hereditary material in humans and almost all other organisms. From the color of our eyes to our predisposition to certain diseases, DNA dictates a vast array of traits.
It's a complex molecule, but its functionality hinges on a select group of components.
The Central Role of Nitrogenous Bases
At the heart of DNA's coding system lie the nitrogenous bases. These organic molecules, containing nitrogen, are the fundamental units that encode genetic information.
Like letters in an alphabet, the sequence of these bases spells out the instructions for building proteins and regulating cellular processes. Without them, DNA would be a lifeless strand, incapable of carrying the information necessary for life.
These bases aren't just components; they are the very essence of genetic information. They determine everything from the structure of proteins to the regulation of gene expression.
Unlocking Life's Secrets: Why Understanding Nitrogenous Bases Matters
To truly grasp the intricacies of life, from the simplest bacteria to the most complex human being, we must first understand the language of nitrogenous bases. Their interactions, their sequences, and their subtle variations hold the keys to understanding everything from genetic diseases to the very origins of life.
By delving into the world of these molecular building blocks, we gain a deeper appreciation for the elegance and complexity of the biological world. Understanding nitrogenous bases isn't just about science; it's about understanding life itself.
Life, in all its astonishing complexity and diversity, is underpinned by a remarkably simple code. This code, the blueprint for every living organism, resides within the elegant structure of DNA (Deoxyribonucleic Acid).
Think of DNA as the instruction manual for building and operating a living thing. Understanding its components is key to unlocking the secrets of life itself.
DNA is the hereditary material in humans and almost all other organisms. From the color of our eyes to our predisposition to certain diseases, DNA dictates a vast array of traits.
It's a complex molecule, but its functionality hinges on a select group of components.
At the heart of DNA's coding system lie the nitrogenous bases. These organic molecules, containing nitrogen, are the fundamental units that encode genetic information.
Like letters in an alphabet, the sequence of these bases spells out the instructions for building proteins and regulating cellular processes. Without them, DNA would be a lifeless strand, incapable of carrying the information necessary for life.
These bases aren't just components; they are the very essence of genetic information. They determine everything from the structure of proteins to the regulation of gene expression.
To truly grasp the intricacies of life, from the simplest bacteria to the most complex human being, we must first understand the language of nitrogenous bases. Their interactions, their sequences, and their subtle variations hold the keys to understanding everything. Let's delve into the essence of these molecular players and unravel their significance.
What are Nitrogenous Bases? Defining the Players
Nitrogenous bases are the cornerstone of genetic coding. They are the reason DNA can store and transmit hereditary information.
These remarkable molecules are organic compounds, meaning they are carbon-based, and they contain nitrogen atoms.
The nitrogen atoms give them their basic, or alkaline, properties. Hence the name "nitrogenous base."
The Five Key Players
There are five primary nitrogenous bases that are essential for life as we know it. Each plays a unique role in the structure and function of nucleic acids—DNA and RNA.
These five bases are Adenine (A), Guanine (G), Cytosine (C), Thymine (T), and Uracil (U).
Adenine (A)
Adenine is a crucial component of both DNA and RNA. It always pairs with either Thymine (T) in DNA or Uracil (U) in RNA.
Guanine (G)
Guanine is also found in both DNA and RNA. It forms a strong bond with Cytosine (C).
Cytosine (C)
Cytosine is another base present in both DNA and RNA. It always pairs with Guanine (G).
Thymine (T)
Thymine is primarily found in DNA. It is the base that pairs with Adenine (A) in the classic DNA double helix.
Uracil (U)
Uracil takes the place of Thymine in RNA. Therefore, it pairs with Adenine (A) in RNA molecules.
Basic Chemical Structure
While each nitrogenous base has its unique chemical structure, they all share a common foundation. They consist of a nitrogen-containing ring structure that can attach to a sugar molecule and a phosphate group to form a nucleotide.
Understanding these basic structures is vital for comprehending how they interact to form DNA and RNA, and how they encode genetic information.
Life's genetic language, written in the sequence of nitrogenous bases, builds upon a foundation of structural chemistry. It's not enough to simply know which bases exist; to truly appreciate their function, we must understand their structural organization. These bases are not all created equal; they fall into two distinct families, each characterized by a unique ring structure.
Purines and Pyrimidines: Two Families of Bases
The five nitrogenous bases, Adenine (A), Guanine (G), Cytosine (C), Thymine (T), and Uracil (U), are further classified into two major categories: purines and pyrimidines. This categorization is based on their fundamental molecular structure – specifically, the number of carbon-nitrogen rings they possess. Understanding these structural differences is key to understanding how DNA and RNA assemble and function.
Purines: The Double-Ringed Structures
Purines are characterized by their double-ring structure, consisting of a six-membered ring fused to a five-membered ring. This more complex structure contributes to their larger size compared to pyrimidines.
The two purines found in nucleic acids are Adenine (A) and Guanine (G).
Their double-ringed architecture plays a crucial role in the structure of DNA, contributing to the consistent width of the DNA double helix when pairing with the smaller pyrimidines.
Pyrimidines: The Single-Ringed Structures
In contrast to purines, pyrimidines possess a single six-membered ring structure. This simpler structure makes them smaller than the purines.
The three pyrimidines of biological importance are Cytosine (C), Thymine (T), and Uracil (U). Cytosine is found in both DNA and RNA, while Thymine is primarily found in DNA, and Uracil is primarily found in RNA.
Thymine vs. Uracil: A Subtle but Significant Difference
While Thymine and Uracil are both pyrimidines and share a similar structure, there's a crucial difference: Thymine has a methyl group (CH3) attached to its ring, whereas Uracil does not.
This seemingly small difference has significant implications for DNA stability and function. The presence of the methyl group in Thymine makes it more resistant to chemical degradation, which is important for the long-term storage of genetic information in DNA.
Uracil, lacking this protection, is better suited for the more transient role of RNA. The cell can easily distinguish and remove Uracil from DNA, should it appear due to spontaneous deamination of Cytosine. This repair mechanism helps maintain the integrity of the genetic code.
Nitrogenous Bases in DNA and RNA: A Structural Comparison
We’ve established the fundamental classification of nitrogenous bases as either purines or pyrimidines, distinguished by their ring structures. Now, let’s explore how these bases contribute to the overall architecture of the two primary nucleic acids: DNA and RNA. The incorporation of these bases into DNA and RNA molecules is key to their distinct functions in the cell.
DNA (Deoxyribonucleic Acid): The Blueprint of Life
DNA, or deoxyribonucleic acid, serves as the long-term repository of genetic information in most living organisms. Its structural elegance is directly tied to the properties of its constituent nitrogenous bases.
Nucleotide Formation in DNA
Nitrogenous bases don't exist in isolation within DNA. Instead, they are covalently linked to a deoxyribose sugar molecule and a phosphate group.
This combination forms a nucleotide, the fundamental building block of DNA. The specific nitrogenous base attached determines the identity of the nucleotide (e.g., adenine nucleotide, guanine nucleotide, etc.).
The Double Helix: A Masterpiece of Molecular Architecture
DNA's iconic double helix structure arises from the arrangement of these nucleotides. Two strands of DNA, each composed of a string of nucleotides, wind around each other.
The sugar and phosphate groups form the sugar-phosphate backbone, providing structural support. The nitrogenous bases project inward from this backbone, where they engage in specific pairing interactions.
Base Pairing Rules: The Foundation of Genetic Information
The base pairing rules are crucial to DNA's structure and function. Adenine (A) on one strand always pairs with Thymine (T) on the opposite strand.
Similarly, Guanine (G) always pairs with Cytosine (C). These pairings are mediated by hydrogen bonds, which provide stability to the double helix.
This specific pairing ensures that the two strands of DNA are complementary. This is crucial for accurate DNA replication and information transfer.
RNA (Ribonucleic Acid): The Versatile Messenger
RNA, or ribonucleic acid, plays diverse roles in the cell, primarily related to gene expression. While sharing similarities with DNA, RNA exhibits key structural differences that influence its function.
Nucleotide Formation in RNA
Similar to DNA, RNA is composed of nucleotides. However, in RNA, the sugar is ribose instead of deoxyribose.
A nitrogenous base is linked to a ribose sugar and a phosphate group. This forms an RNA nucleotide.
Structural Differences Between RNA and DNA
The most apparent difference between RNA and DNA is that RNA is typically single-stranded, unlike DNA's double helix. This single-stranded nature allows RNA to fold into complex three-dimensional structures.
This folding is essential for its various functions. Furthermore, the sugar in RNA nucleotides is ribose, which has an extra hydroxyl (OH) group compared to deoxyribose in DNA.
This seemingly small difference makes RNA more reactive than DNA, contributing to its transient nature.
Uracil: RNA's Unique Base
Another critical distinction is the presence of Uracil (U) in RNA instead of Thymine (T). Uracil, like Thymine, pairs with Adenine, but it lacks the methyl group present in Thymine.
This difference affects the stability and interactions of RNA molecules. Uracil's presence in RNA is a key identifier. It helps enzymes distinguish between RNA and DNA during cellular processes.
We’ve established the fundamental classification of nitrogenous bases as either purines or pyrimidines, distinguished by their ring structures. Now, let’s explore how these bases contribute to the overall architecture of the two primary nucleic acids: DNA and RNA. The incorporation of these bases into DNA and RNA molecules is key to their distinct functions in the cell.
Base Pairing: The Key to Genetic Information Storage and Replication
The structure of DNA, with its inherent ability to store and replicate vast amounts of genetic information, hinges on a deceptively simple principle: base pairing. This highly specific interaction between nitrogenous bases is the cornerstone of both DNA's stability and its capacity to accurately transmit genetic information across generations.
The Specificity of Base Pairing
Base pairing isn't a free-for-all. It's a highly regulated process governed by the shapes and chemical properties of the nitrogenous bases themselves.
In DNA, adenine (A) always pairs with thymine (T), and guanine (G) always pairs with cytosine (C). This A-T and G-C pairing is not arbitrary; it's dictated by the number of hydrogen bonds each pair can form.
Adenine and thymine form two hydrogen bonds, while guanine and cytosine form three. This difference in hydrogen bonding contributes to the overall stability of the DNA double helix.
In RNA, the rules are slightly modified. Since thymine (T) is typically replaced by uracil (U), adenine (A) pairs with uracil (U). Guanine (G) still pairs with cytosine (C), maintaining the same three hydrogen bonds.
Hydrogen Bonds: The Glue of the Double Helix
These pairings are not just about chemical compatibility; they're about stability. The hydrogen bonds formed between the base pairs act like molecular glue, holding the two strands of the DNA double helix together.
Without these hydrogen bonds, the DNA molecule would be unstable and prone to falling apart, which would compromise its ability to store and replicate genetic information.
The number of hydrogen bonds also affects the stability of the base pairs. G-C pairs, with their three hydrogen bonds, are more stable than A-T pairs, which have only two. Regions of DNA rich in G-C pairs are therefore more resistant to denaturation (strand separation).
Chargaff's Rules: Unveiling the Quantitative Basis of Base Pairing
Before the structure of DNA was fully elucidated, biochemist Erwin Chargaff made a critical observation. He noted that the amount of adenine in a DNA molecule is always approximately equal to the amount of thymine, and the amount of guanine is always approximately equal to the amount of cytosine.
These observations, known as Chargaff's rules, provided crucial evidence supporting the base pairing rules. Chargaff’s work, although not initially understood in its full context, was instrumental in Watson and Crick's discovery of the double helix structure.
Chargaff's rules are a direct consequence of the A-T and G-C pairing. If every adenine is paired with a thymine, and every guanine is paired with a cytosine, then their amounts must necessarily be equal.
In essence, Chargaff's rules provided a quantitative foundation for the qualitative observation of base pairing, solidifying our understanding of how genetic information is stored and replicated.
We’ve established the fundamental classification of nitrogenous bases as either purines or pyrimidines, distinguished by their ring structures. Now, let’s explore how these bases contribute to the overall architecture of the two primary nucleic acids: DNA and RNA. The incorporation of these bases into DNA and RNA molecules is key to their distinct functions in the cell.
From Code to Protein: The Genetic Code and its Translation
The sequence of nitrogenous bases, that we have been discussing thus far, isn't just a random assortment. It is, in fact, the very language of life, forming what we know as the genetic code. This code, ingeniously simple yet profoundly powerful, holds the instructions for building and maintaining every living organism.
But how does a sequence of As, Ts, Cs, and Gs (or Us in RNA) translate into the complex machinery of a cell, including the proteins that perform nearly every essential function? The answer lies in the intricate processes of transcription and translation, the twin pillars of the Central Dogma of Molecular Biology.
Cracking the Code: From Nitrogenous Bases to Codons
The genetic code is not read letter by letter, but in triplets. Each three-nucleotide sequence, known as a codon, specifies a particular amino acid. With four different bases, there are 64 possible codons (4 x 4 x 4 = 64).
This is more than enough to code for the 20 amino acids commonly found in proteins. As a result, the genetic code is degenerate, meaning that most amino acids are specified by more than one codon. This redundancy provides a buffer against mutations.
Some codons don't code for amino acids at all, but rather act as signals. Specifically, start codons (most commonly AUG) initiate protein synthesis, while stop codons (UAA, UAG, and UGA) terminate it.
Think of the genetic code as a dictionary. Codons are the words, and amino acids are the definitions. The order of the codons in a gene determines the order of the amino acids in the resulting protein.
The Central Dogma: DNA to RNA to Protein
The flow of genetic information within a biological system, according to the Central Dogma, moves from DNA to RNA to protein. This may be an oversimplification for some biological phenomena, but remains a critical understanding for molecular biology.
-
Transcription: This process involves copying the genetic information from DNA into a messenger RNA (mRNA) molecule.
The DNA sequence of a gene is used as a template to synthesize a complementary mRNA sequence. This mRNA molecule then carries the genetic instructions from the nucleus (in eukaryotes) to the ribosomes in the cytoplasm.
-
Translation: This process is where the magic truly happens.
Here, the mRNA sequence is "read" by ribosomes, which use transfer RNA (tRNA) molecules to bring the correct amino acids to the ribosome. These amino acids are then linked together, one by one, to form a polypeptide chain. This polypeptide chain then folds into a functional protein.
From Blueprint to Building: How the Genetic Code Dictates Protein Structure
The genetic code is the master blueprint. It dictates the precise sequence of amino acids that make up a protein. This sequence, in turn, determines the protein's three-dimensional structure and, ultimately, its function.
A change in even a single nitrogenous base within a gene can alter the corresponding codon, potentially leading to a different amino acid being incorporated into the protein. This seemingly small change can have dramatic consequences, affecting the protein's folding, stability, and activity.
Such mutations are the raw material of evolution, driving the adaptation of organisms to their environments. They can also be the root cause of genetic diseases, underscoring the profound importance of maintaining the integrity of the genetic code.
The Broad Impact: Nitrogenous Bases in Biological Processes
The intricate dance of life, from the simplest bacterium to the most complex organism, hinges on the precise orchestration of molecular events. Among the most critical players in this performance are the nitrogenous bases.
These seemingly simple molecules, the fundamental units of the genetic code, exert a profound influence on essential biological processes. They ensure faithful DNA replication, drive protein synthesis, and safeguard the integrity and functionality of the genome.
Nitrogenous Bases: Cornerstones of DNA Replication
DNA replication is the bedrock of heredity, ensuring the accurate transmission of genetic information from one generation to the next. Nitrogenous bases are not merely passive components in this process; they are active participants.
Their specific pairing rules (A with T, and G with C) dictate the order in which new nucleotides are added to the growing DNA strand. This ensures that the newly synthesized DNA molecule is an exact replica of the original.
Without this precise base-pairing mechanism, errors would accumulate rapidly, leading to mutations and potentially catastrophic consequences for the cell.
The enzyme DNA polymerase relies on these base-pairing rules to select the correct nucleotide to add to the growing strand. This selection process ensures fidelity and the accurate duplication of the genome.
Protein Synthesis: Orchestrating the Cellular Workforce
The central dogma of molecular biology describes the flow of genetic information from DNA to RNA to protein. Nitrogenous bases play a crucial role in both transcription (DNA to RNA) and translation (RNA to protein).
In transcription, the sequence of nitrogenous bases in DNA serves as a template for the synthesis of messenger RNA (mRNA).
The mRNA molecule then carries this genetic information to the ribosomes, where it is translated into a specific sequence of amino acids, forming a protein.
Each three-base-pair codon on the mRNA molecule corresponds to a particular amino acid, and the sequence of these codons dictates the order in which amino acids are linked together.
The accurate translation of the genetic code relies entirely on the correct identification and decoding of these codons, which are defined by the sequence of nitrogenous bases.
Preserving Genomic Integrity: The Guardian Role
The genome, the complete set of genetic instructions in an organism, is a precious and vulnerable entity.
Nitrogenous bases contribute significantly to the overall function and stability of the genome. They participate in various DNA repair mechanisms to ensure the genome remains intact.
The integrity of the base sequence is paramount for proper cellular function and survival. Modified or damaged bases can lead to mutations and genomic instability.
Cells have evolved intricate mechanisms to detect and repair these lesions. These mechanisms often involve the removal and replacement of the affected base, ensuring the preservation of the genetic code.
Nitrogenous bases and their interactions are crucial to maintain genome stability, and their modifications can play roles in disease.

FAQs: Nitrogenous Bases and DNA
Here are some frequently asked questions about nitrogenous bases and their role in DNA.
What exactly are nitrogenous bases?
Nitrogenous bases are organic molecules containing nitrogen that act as the fundamental building blocks of DNA and RNA. There are five main nitrogenous bases: Adenine (A), Guanine (G), Cytosine (C), Thymine (T, in DNA), and Uracil (U, in RNA).
How do nitrogenous bases pair up in DNA?
In DNA, adenine (A) always pairs with thymine (T), and guanine (G) always pairs with cytosine (C). This specific pairing is due to the number of hydrogen bonds each pair can form, ensuring the double helix structure of DNA remains stable.
Why are nitrogenous bases important for storing genetic information?
The sequence of nitrogenous bases along a DNA strand acts as a code, much like letters in an alphabet. This sequence determines the genetic instructions needed to build and maintain an organism. The order of these nitrogenous bases is what specifies traits.
How does the presence of uracil differentiate RNA from DNA?
While DNA utilizes the nitrogenous bases adenine, guanine, cytosine, and thymine, RNA substitutes thymine with uracil. Uracil pairs with adenine in RNA, just as thymine does in DNA. This difference is a key characteristic that distinguishes the two types of nucleic acids.