Nitrogenous Bases: DNA & RNA Building Blocks
Nitrogenous bases, the fundamental building blocks of nucleic acids, orchestrate genetic information storage and transfer within biological systems. DNA (Deoxyribonucleic acid) employs adenine, guanine, cytosine, and thymine as its nitrogenous bases, meticulously encoding the genetic instructions necessary for organismal development and function. RNA (Ribonucleic acid), conversely, utilizes uracil in place of thymine to perform diverse cellular roles, including protein synthesis under the direction of the Ribosome. Watson and Crick's groundbreaking model elucidated the specific pairing rules between these nitrogenous bases—adenine with thymine (or uracil in RNA) and guanine with cytosine—underscoring the double-helical structure that dictates DNA replication and transcription fidelity.
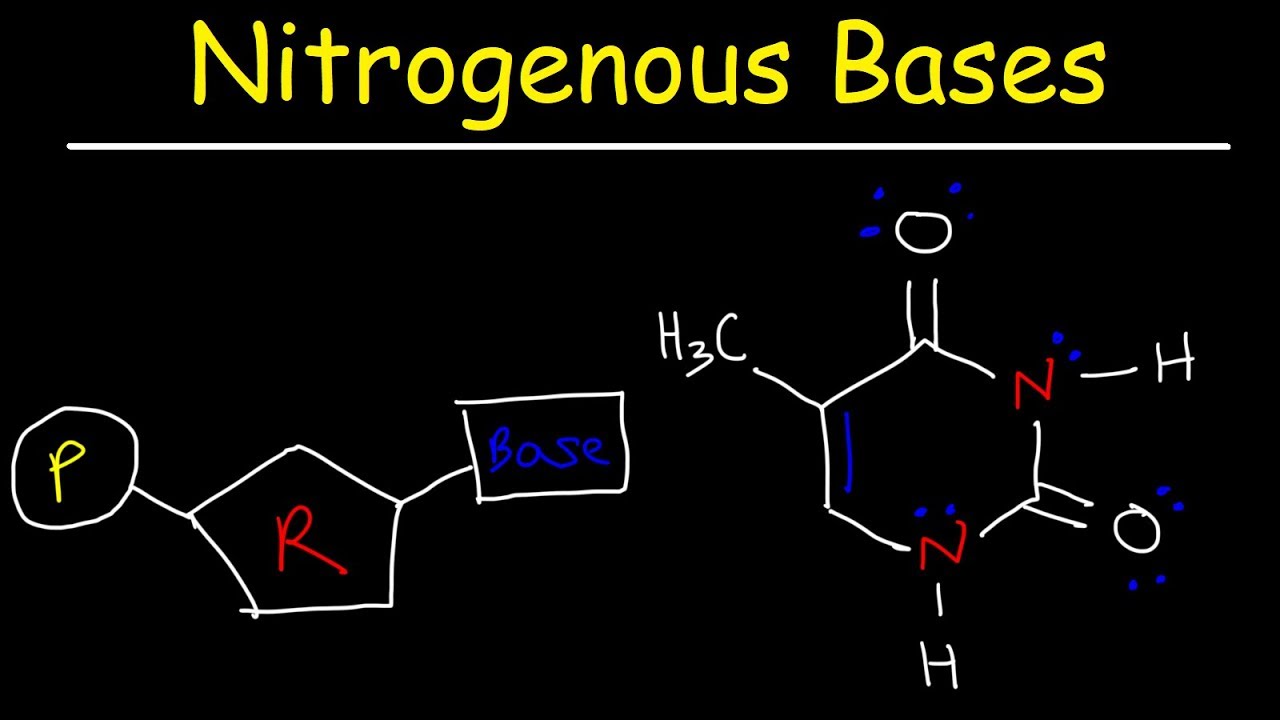
Image taken from the YouTube channel The Organic Chemistry Tutor , from the video titled Nucleosides vs Nucleotides, Purines vs Pyrimidines - Nitrogenous Bases - DNA & RNA .
The Unseen Architects of Life: Nitrogenous Bases
The Foundation of Heredity and Gene Expression
Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) stand as the very foundation upon which life's intricate processes are built. They are the fundamental molecules of heredity and gene expression, orchestrating everything from the development of a single cell to the complexities of an entire organism.
DNA serves as the primary repository of genetic information, carefully encoding the instructions necessary for building and maintaining life. RNA, on the other hand, plays a dynamic role in decoding this information and translating it into functional proteins.
Encoding the Blueprint of Life
At the heart of these molecules lies a set of remarkable compounds known as nitrogenous bases. These bases are not merely structural components; they are the key enablers of genetic information storage and transfer.
It is through the precise sequence of these bases that the genetic code is written. This sequence determines the characteristics that are passed down from one generation to the next. The order of these bases dictates everything from eye color to predisposition to certain diseases.
The nitrogenous bases, adenine (A), guanine (G), cytosine (C), thymine (T), and uracil (U), form the alphabet of the genetic code. Their arrangement along the DNA and RNA strands dictates the synthesis of proteins, which carry out the vast majority of cellular functions.
Unveiling Their Multifaceted Roles
This article aims to embark on a journey of discovery. We'll explore the pivotal roles of nitrogenous bases across various domains of molecular biology. From their structural roles to their advanced biotechnological applications, we will uncover the significance of these molecules.
This exploration will encompass their foundational contributions to the very structure of DNA and RNA. We'll explore the intricate mechanisms by which they facilitate replication, transcription, and translation. Finally, we'll examine their instrumental role in cutting-edge biotechnologies.
The goal is to present a thorough examination of these unsung heroes of molecular biology. We aim to illuminate their crucial functions in maintaining the integrity of life itself.
Decoding the Structure: The Chemical Blueprint of Nitrogenous Bases
From the grand concept of the genome down to the tangibly microscopic scale, the fundamental language of life is written using deceptively simple chemical structures. These are the nitrogenous bases, the information-bearing components of nucleic acids. Understanding their composition and arrangement is crucial to unlocking the secrets of heredity and genetic function. Let's dissect the chemical blueprint of these vital molecules.
The Building Blocks: Nucleotides and Their Components
At the heart of DNA and RNA lie nucleotides. Each nucleotide comprises three essential components: a nitrogenous base, a pentose sugar (deoxyribose in DNA, ribose in RNA), and one or more phosphate groups. The nitrogenous base is the crucial element that dictates the nucleotide's identity and its capacity to engage in base pairing.
The Structure of Nitrogenous Bases
Nitrogenous bases are heterocyclic aromatic compounds, characterized by a ring structure containing nitrogen atoms. The arrangement of these atoms and the attached functional groups distinguishes each base and determines its unique properties. These structures are not static; their inherent flexibility allows for a dynamic interaction within the DNA and RNA molecules.
Linking Bases to Sugars: The Glycosidic Bond
The nitrogenous base doesn't exist in isolation within a nucleotide. It is covalently linked to the pentose sugar through a N-glycosidic bond. In DNA, this bond connects the nitrogen atom at position 9 of a purine or position 1 of a pyrimidine to the 1' carbon of deoxyribose. A similar linkage occurs in RNA, connecting the base to ribose. This linkage is critical; it provides the structural backbone upon which the genetic code is built.
From Nucleoside to Nucleotide: Adding Phosphate
The addition of one or more phosphate groups to the sugar component transforms a nucleoside (base + sugar) into a nucleotide. These phosphate groups are attached to the 5' carbon of the pentose sugar. The resulting nucleotide is now equipped with the energy currency needed for polymerization into nucleic acids. These phosphate groups are also responsible for the overall negative charge of DNA and RNA, a crucial factor in their interactions with other molecules.
Purines and Pyrimidines: Two Families of Bases
Nitrogenous bases are classified into two main families: purines and pyrimidines. This classification is based on their distinct ring structures.
Purines: Adenine and Guanine
Purines, adenine (A) and guanine (G), are characterized by a double-ring structure. This consists of a six-membered pyrimidine ring fused to a five-membered imidazole ring. This more complex structure contributes to their larger size compared to pyrimidines.
Pyrimidines: Cytosine, Thymine, and Uracil
Pyrimidines, cytosine (C), thymine (T), and uracil (U), possess a single six-membered pyrimidine ring. While cytosine is found in both DNA and RNA, thymine is specific to DNA, and uracil replaces thymine in RNA. This seemingly minor difference plays a significant role in RNA's structural flexibility and functional diversity.
Hydrogen Bonding: The Glue of the Double Helix
The stability of DNA's double helix hinges on the precise pairing of nitrogenous bases through hydrogen bonds. These bonds are weak individually. However, their cumulative effect is critical for holding the two strands together.
Adenine forms two hydrogen bonds with thymine (A=T), while guanine forms three hydrogen bonds with cytosine (G≡C). The difference in the number of hydrogen bonds between A-T and G-C pairs contributes to the overall stability of the double helix. The G-C pair is more stable due to its additional hydrogen bond.
Chargaff's Rules: Unveiling the Base Pairing Ratios
Erwin Chargaff's experiments revealed fundamental relationships between the amounts of each base in DNA. He found that the amount of adenine is always equal to the amount of thymine (A=T), and the amount of guanine is always equal to the amount of cytosine (G=C).
These rules provided crucial evidence for the base pairing principles that underpin DNA structure and replication. Chargaff's work was instrumental in Watson and Crick's elucidation of the double helix, demonstrating that the seemingly simple ratios of bases held a profound secret about the nature of the genetic code.
The Double Helix Unveiled: Nitrogenous Bases in DNA Structure and Replication
From the grand concept of the genome down to the tangibly microscopic scale, the fundamental language of life is written using deceptively simple chemical structures. These are the nitrogenous bases, the information-bearing components of nucleic acids. Understanding their composition and interaction is paramount to understanding life itself. This section delves into the architecture of DNA, the iconic double helix, and the crucial role nitrogenous bases play in its structure and accurate replication.
The Discovery and Structure of the Double Helix
The discovery of DNA's double helix structure stands as a monumental achievement in the history of science. While James Watson and Francis Crick are often credited with the discovery, it is imperative to acknowledge the indispensable contributions of Rosalind Franklin and Maurice Wilkins.
Franklin's X-ray diffraction images, particularly "Photo 51," provided crucial evidence about the helical structure of DNA. This evidence was instrumental in Watson and Crick's subsequent model building. It is a stark reminder of the collaborative, and sometimes inequitable, nature of scientific discovery.
The double helix model revealed that DNA consists of two intertwined strands, each composed of a sugar-phosphate backbone. These strands are linked by nitrogenous bases that project inward, forming complementary pairs.
The Specificity of Base Pairing: A-T and G-C
One of the most profound revelations of the double helix model was the specificity of base pairing. Adenine (A) invariably pairs with Thymine (T), and Guanine (G) invariably pairs with Cytosine (C). This exclusive pairing is dictated by the chemical structures of the bases and their ability to form stable hydrogen bonds.
Adenine and thymine form two hydrogen bonds, while guanine and cytosine form three.
This difference in hydrogen bonding contributes to the overall stability of the DNA double helix. The consistent pairing ensures that the genetic code is faithfully maintained during DNA replication.
DNA as the Primary Carrier of Genetic Information
DNA serves as the repository of an organism's genetic blueprint, directing all cellular processes. Its ability to accurately store and transmit information stems directly from the arrangement of its nitrogenous bases.
The sequence of these bases encodes the instructions for synthesizing proteins and regulating gene expression. This arrangement dictates an organism's traits and characteristics.
The stability of the double helix structure, coupled with the precision of base pairing, is essential for preserving the integrity of this genetic information across generations. Errors in replication or damage to the DNA can lead to mutations, with potentially detrimental consequences.
Replication: Maintaining the Integrity of the Genetic Code
DNA replication is the process by which a cell duplicates its DNA before cell division. This process is remarkably accurate, thanks to the precise base pairing rules and the activity of DNA polymerase, an enzyme that catalyzes DNA synthesis.
During replication, the double helix unwinds, and each strand serves as a template for the synthesis of a new complementary strand. DNA polymerase meticulously matches the appropriate nitrogenous base to each base on the template strand, ensuring that the new DNA molecule is an accurate copy of the original.
The fidelity of DNA replication is paramount for maintaining genetic stability and preventing mutations. The process involves multiple proofreading mechanisms to correct any errors that may occur during synthesis. These mechanisms are critical for ensuring the integrity of the genome.
The precise and controlled interplay of nitrogenous bases in the double helix structure and replication process is essential for life as we know it. Without their consistent pairing and accurate duplication, the transmission of genetic information would be compromised, leading to chaos at the cellular level.
RNA's Multifaceted Role: Transcription and Translation Explained
From the grand concept of the genome down to the tangibly microscopic scale, the fundamental language of life is written using deceptively simple chemical structures. These are the nitrogenous bases, the information-bearing components of nucleic acids. Understanding their multifaceted roles in RNA, particularly within transcription and translation, reveals the dynamic mechanisms of gene expression.
DNA vs. RNA: A Structural Comparison
While DNA serves as the stable repository of genetic information, RNA functions as its versatile messenger and interpreter.
This functional divergence is mirrored in their structural differences. Most notably, RNA replaces thymine (T) with uracil (U), a subtle alteration with significant implications for base pairing and molecular interactions.
RNA also features a ribose sugar in its nucleotide backbone, distinguishing it from DNA's deoxyribose. The presence of an extra hydroxyl group in ribose contributes to RNA's greater flexibility and susceptibility to degradation.
These structural distinctions underscore RNA's dynamic role in cellular processes.
Transcription: From DNA Template to RNA Transcript
Transcription is the process by which RNA is synthesized from a DNA template. This is where the code held so securely by the structure of DNA gets its first chance at expression.
It's a tightly regulated process catalyzed by RNA polymerase, an enzyme that binds to specific DNA sequences (promoters) and unwinds the double helix to initiate RNA synthesis.
The resulting RNA molecule, known as the primary transcript, undergoes further processing (splicing, capping, and tailing) to generate mature messenger RNA (mRNA).
mRNA then carries the genetic message from the nucleus to the ribosomes, where translation takes place.
Transcription is the initial step in gene expression, dictating which genes are activated and transcribed into RNA.
Translation: Decoding the Genetic Code
Translation is the process of decoding mRNA codons into amino acid sequences, thus the creation of a protein.
Ribosomes are the molecular machines that orchestrate this complex process, reading the mRNA sequence in three-nucleotide units called codons. Each codon specifies a particular amino acid or signals the start or stop of translation.
Transfer RNA (tRNA) molecules act as adaptors, each carrying a specific amino acid and recognizing a corresponding codon on the mRNA through a complementary anticodon sequence.
The genetic code, which defines the relationship between codons and amino acids, is largely universal across all organisms, highlighting the shared ancestry of life.
The Genetic Code: Degeneracy and Specificity
The genetic code exhibits degeneracy, meaning that multiple codons can specify the same amino acid.
This redundancy provides a buffer against mutations, as some base changes may not alter the amino acid sequence of the resulting protein.
However, the genetic code is also highly specific, with each codon specifying only one amino acid.
This ensures the accurate translation of genetic information into functional proteins. The fidelity of translation is crucial for maintaining cellular homeostasis and preventing disease.
When Things Go Wrong: Mutations and Genetic Variation Arising from Altered Bases
[RNA's Multifaceted Role: Transcription and Translation Explained From the grand concept of the genome down to the tangibly microscopic scale, the fundamental language of life is written using deceptively simple chemical structures. These are the nitrogenous bases, the information-bearing components of nucleic acids. Understanding their multifaceted role in encoding, transmitting, and expressing genetic information is paramount, but equally crucial is understanding what happens when the system deviates from its intended state. These deviations, known as mutations, are the engine of evolution, but also the source of countless genetic disorders.]
The Nature and Genesis of Mutations
Mutations, at their core, represent alterations to the nucleotide sequence of DNA. They can arise spontaneously due to errors in DNA replication or repair, or they can be induced by external factors known as mutagens.
These mutagens include a wide array of agents, ranging from radiation (UV light, X-rays) to chemical substances (certain industrial compounds, natural toxins). The inherent instability of certain nitrogenous bases can also contribute to spontaneous mutations.
The rate at which mutations occur is generally low, thanks to sophisticated DNA repair mechanisms that constantly patrol the genome, correcting errors as they arise. However, no system is perfect, and some mutations inevitably slip through the cracks, becoming a permanent part of the genetic code.
A Spectrum of Errors: Classifying Mutations
Mutations are not a monolithic entity; they come in various forms, each with its own distinct characteristics and potential consequences. Understanding these different types is crucial for comprehending their impact on protein structure and function.
Point Mutations: Subtle Changes, Significant Effects
Point mutations are alterations that affect a single nucleotide base. These mutations can be further subdivided into:
- Substitutions: Where one base is replaced by another. These substitutions can be further classified as transitions (purine replaced by purine, or pyrimidine replaced by pyrimidine) or transversions (purine replaced by pyrimidine, or vice versa).
- Insertions: Where an extra nucleotide is added into the DNA sequence.
- Deletions: Where a nucleotide is removed from the DNA sequence.
Frameshift Mutations: A Cascade of Errors
Insertions and deletions, particularly those that do not involve multiples of three nucleotides, can lead to frameshift mutations.
These mutations disrupt the reading frame of the genetic code, causing all subsequent codons to be misread. The result is often a completely different amino acid sequence downstream of the mutation, leading to a non-functional or truncated protein.
Chromosomal Mutations: Large-Scale Alterations
While point mutations affect individual nucleotides, chromosomal mutations involve large-scale changes in chromosome structure or number. These can include:
- Deletions: Loss of a segment of a chromosome.
- Duplications: Repetition of a segment of a chromosome.
- Inversions: Reversal of a segment of a chromosome.
- Translocations: Movement of a segment of a chromosome to a different chromosome.
From Code to Consequence: The Impact of Mutations
The consequences of mutations are highly variable, depending on the nature and location of the mutation within the genome. Some mutations may have no discernible effect, while others can be devastating.
- Silent Mutations: These mutations change a codon but do not alter the amino acid sequence of the protein due to the redundancy of the genetic code.
- Missense Mutations: These mutations result in the incorporation of a different amino acid into the protein. The effect of a missense mutation can range from mild to severe, depending on the chemical properties of the substituted amino acid and its location within the protein.
- Nonsense Mutations: These mutations introduce a premature stop codon, leading to a truncated and often non-functional protein.
Mutations as the Catalyst of Genetic Variation
While mutations can have detrimental effects, they are also the ultimate source of genetic variation, the raw material upon which natural selection acts.
By introducing new alleles into a population, mutations provide the opportunity for organisms to adapt to changing environments and evolve over time. Without mutations, all life would be identical, and the remarkable diversity we see around us would not exist.
Therefore, while precision in DNA replication and repair is essential for maintaining the integrity of the genome, the occasional error is also necessary for the long-term survival and evolution of life. It's a delicate balance between stability and change, a testament to the inherent dynamism of the genetic code.
Harnessing the Code: Biotechnological Applications of Nitrogenous Bases
[When Things Go Wrong: Mutations and Genetic Variation Arising from Altered Bases [RNA's Multifaceted Role: Transcription and Translation Explained From the grand concept of the genome down to the tangibly microscopic scale, the fundamental language of life is written using deceptively simple chemical structures. These are the nitrogenous bases, the...]
The inherent specificity of these bases, dictated by their structure and complementary binding affinities, has been ingeniously exploited across numerous biotechnological applications. Two of the most prominent examples are Polymerase Chain Reaction (PCR) and DNA sequencing, both of which have revolutionized fields ranging from diagnostics to personalized medicine.
Polymerase Chain Reaction (PCR): Amplifying the Blueprint of Life
PCR, conceived by Kary Mullis, stands as a monumental achievement in molecular biology. The technique allows for the rapid amplification of specific DNA sequences, generating billions of copies from a minute starting sample.
At its core, PCR relies fundamentally on the precise base-pairing of nitrogenous bases. Short, synthetic DNA sequences called primers are designed to bind to specific regions flanking the target DNA sequence.
These primers, obeying the A-T and G-C rules, guide the DNA polymerase enzyme to initiate replication. Through repeated cycles of heating and cooling, combined with the action of the polymerase, the target sequence is exponentially amplified.
Applications Across Disciplines
The impact of PCR spans numerous disciplines. In diagnostics, it is used to detect pathogens, identify genetic diseases, and monitor treatment efficacy.
In forensics, PCR enables the analysis of trace amounts of DNA recovered from crime scenes, providing crucial evidence for investigations. Furthermore, PCR is an indispensable tool in research, facilitating gene cloning, mutation analysis, and the study of gene expression.
DNA Sequencing: Reading the Code
DNA sequencing technologies enable the determination of the precise order of nitrogenous bases within a DNA molecule. This capability has opened unprecedented avenues for understanding the genetic basis of life.
Sanger Sequencing: The Pioneering Approach
The Sanger sequencing method, developed in the 1970s, was the first widely adopted approach for determining DNA sequences. This technique utilizes modified nucleotides, called dideoxynucleotides, that terminate DNA synthesis upon incorporation.
By analyzing the fragments produced, researchers can deduce the sequence of the original DNA molecule. While still used today, it has largely been superseded by next-generation methods.
Next-Generation Sequencing (NGS): A Revolution in Throughput
Next-Generation Sequencing (NGS) technologies have revolutionized the field of genomics. NGS platforms allow for the simultaneous sequencing of millions or even billions of DNA fragments, dramatically increasing throughput and reducing costs.
These technologies employ various approaches, including massively parallel sequencing and sequencing by synthesis, to rapidly determine the order of nitrogenous bases in complex genomes.
NGS has transformed biological research, enabling large-scale genomic studies, personalized medicine, and the identification of novel drug targets. The ability to sequence entire genomes rapidly and cost-effectively is driving a new era of biological discovery.
From the grand concept of the genome down to the tangibly microscopic scale, the fundamental language of life is written using decoding nitrogenous bases. Understanding how these bases operate within the full context of the genome has revolutionized biological research and is the focus of our next critical examination.
The Big Picture: Genomics, the Human Genome Project, and Beyond
The advent of high-throughput DNA and RNA sequencing technologies has provided an unprecedented capability to explore the entire genome. The implications are profound, marking a paradigm shift in how we approach biology.
Significance of Genome-Wide Sequencing
DNA and RNA sequencing is no longer just about identifying individual genes; it is about understanding the complex interplay of all genetic elements within an organism. This comprehensive view provides insights into gene regulation, evolutionary history, and disease mechanisms that were previously inaccessible.
The Human Genome Project: A Foundational Endeavor
The Human Genome Project (HGP) was a monumental achievement that mapped the entire human genome. Its completion marked a turning point in biology, providing a reference sequence that has become the cornerstone for countless research endeavors.
The HGP demonstrated the feasibility of sequencing entire genomes and spurred technological advancements that have made sequencing faster and more affordable. This has directly impacted our understanding of human biology and disease.
Direct Impacts of the Human Genome Project
-
Disease Understanding: It facilitated the identification of genes associated with various diseases, including cancer, Alzheimer's, and cystic fibrosis.
-
Personalized Medicine: It paved the way for personalized medicine approaches, where treatments are tailored to an individual's genetic makeup.
-
Drug Development: It accelerated drug discovery by providing targets for therapeutic intervention.
The Roles of Genomics, Proteomics, and Bioinformatics
The deluge of data generated by genomics necessitates the integration of other disciplines.
Genomics focuses on the complete set of genes and their interactions.
Proteomics investigates the complete set of proteins produced by an organism, including their structure, function, and interactions.
Bioinformatics provides the computational tools and analytical methods to manage, analyze, and interpret vast datasets.
By integrating these fields, researchers gain a more holistic understanding of biological systems, moving beyond individual genes to the complex networks of interactions that govern cellular function.
Analyzing Nitrogenous Base Data
Researchers working in these fields face the challenging task of extracting meaningful information from complex datasets.
This includes identifying patterns in nitrogenous base sequences, predicting gene function, understanding regulatory mechanisms, and identifying genetic variations that contribute to disease.
Sophisticated computational tools and algorithms are essential for this endeavor.
Future Directions
The future of genomics lies in integrating even more data types, such as epigenomics and metabolomics, to create a comprehensive picture of biological systems. This will enable researchers to develop more effective diagnostic tools, personalized treatments, and preventative strategies for a wide range of diseases.
The study of nitrogenous bases within the context of the genome is a rapidly evolving field that promises to transform our understanding of life and revolutionize medicine.
Video: Nitrogenous Bases: DNA & RNA Building Blocks

FAQs: Nitrogenous Bases - DNA & RNA Building Blocks
What's the main difference between nitrogenous bases in DNA and RNA?
DNA uses the nitrogenous bases adenine (A), guanine (G), cytosine (C), and thymine (T). RNA utilizes adenine (A), guanine (G), cytosine (C), but replaces thymine (T) with uracil (U). This single base substitution is a primary difference.
Which nitrogenous bases pair together and why is this important?
In DNA, adenine (A) pairs with thymine (T), and guanine (G) pairs with cytosine (C). In RNA, adenine (A) pairs with uracil (U). This specific pairing is crucial for accurate DNA replication and RNA transcription; the pairings allow for the correct sequences to be copied and created.
What are the two categories of nitrogenous bases?
Nitrogenous bases are categorized into two main types: purines and pyrimidines. Purines (adenine and guanine) have a double-ring structure, while pyrimidines (cytosine, thymine, and uracil) have a single-ring structure. These structural differences affect how the nitrogenous bases interact.
Why are nitrogenous bases considered the building blocks of DNA and RNA?
Nitrogenous bases, along with a sugar and a phosphate group, form nucleotides. Nucleotides are the monomers that link together to create the long chains of DNA and RNA molecules. These chains form the genetic code because the order of nitrogenous bases determines the sequence of genes.
So, next time you're pondering the mysteries of life, remember those tiny but mighty nitrogenous bases! They're the unsung heroes working tirelessly within our DNA and RNA, orchestrating the complex dance that makes us, well, us. Pretty cool, right?
